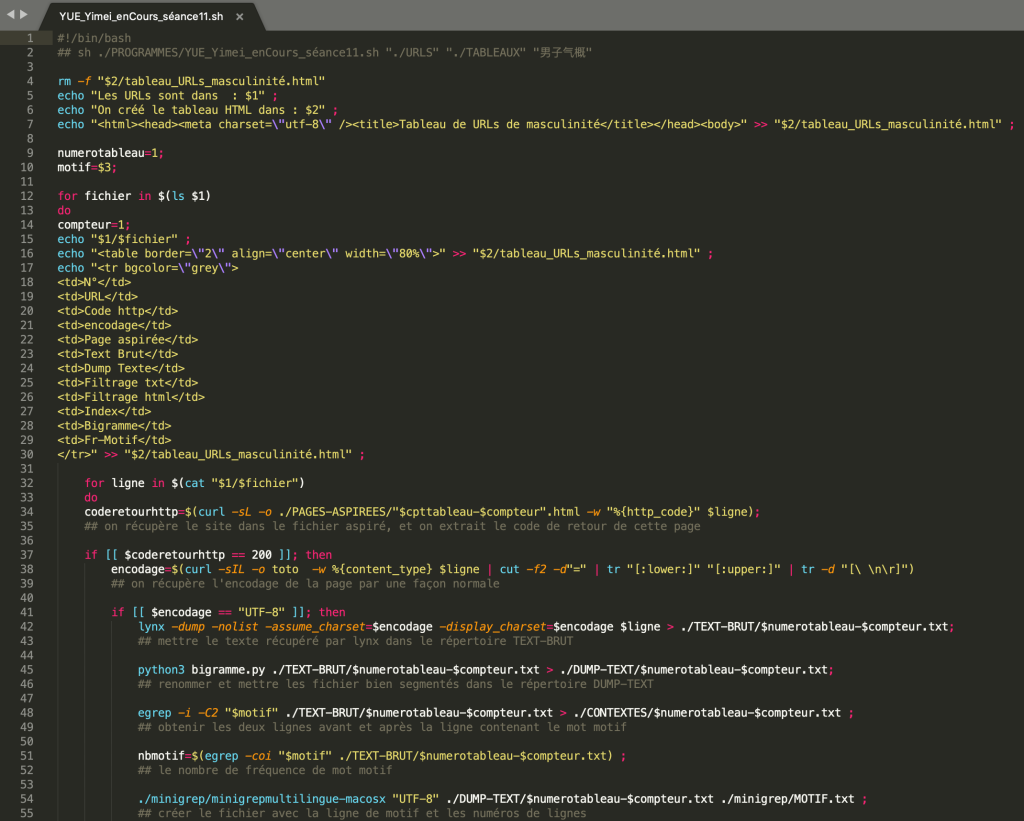
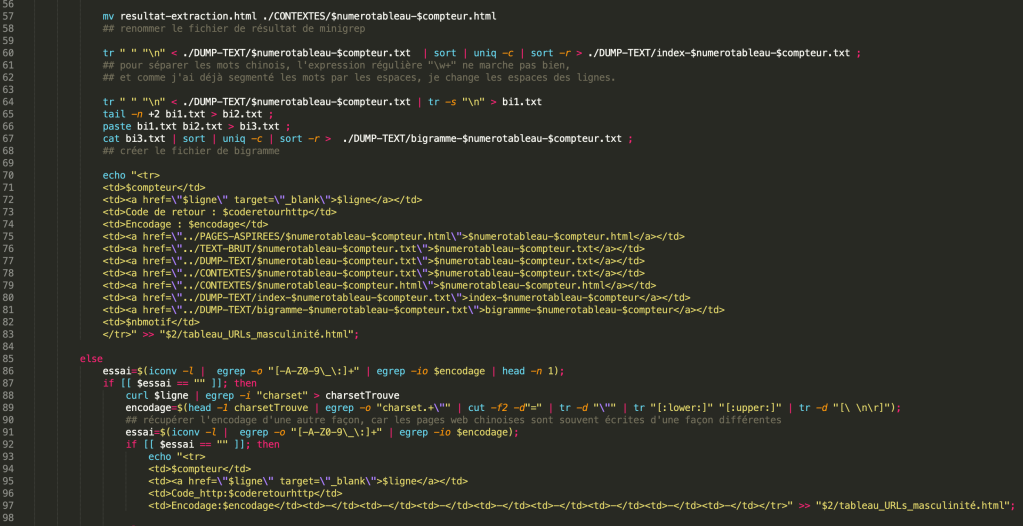
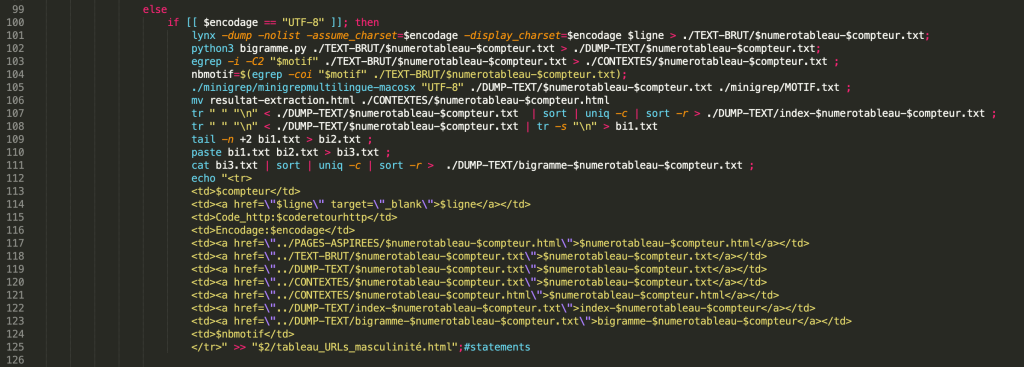
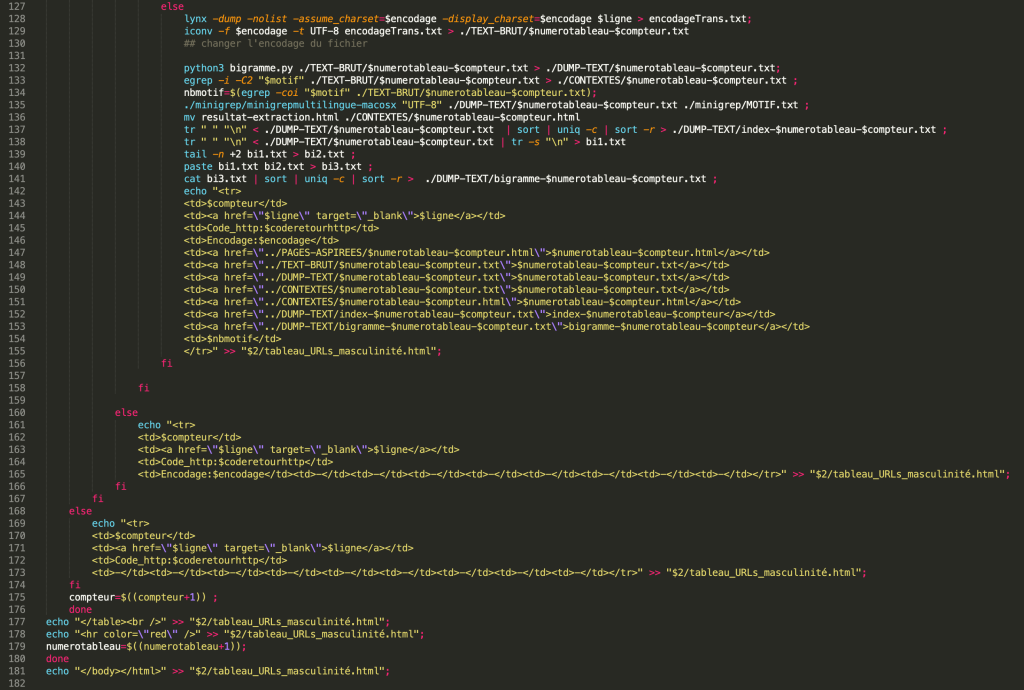
Puisque les URLs en chinois se sont écrits d’une façon différente de ceux en français, surtout dans le domaine d’encodage. Dans ma liste d’URLs, il y a certains URLs sont créés en encodage de « GB2312 ». D’ailleurs, l’encodage de certaines pages web que je récupère en utilisant {content_type} est « TEXT/HTML ».
À ce titre, j’ai traité les URLs chinois séparément et changé un peu la façon de tester l’encodage pour la liste d’URLs chinois. Et voici ma logique :

Dans mon dernier exercice, j’ai fait la segmentation en chinois via l’outil Jieba en écrivant un script de Python.
Mais j’ai rencontré le problème de décoder les bytes en chinois dans les fichiers, certains fichiers peuvent être segmenté normalement, mais la plupart des fichiers ne marchent pas avec mon script de Python.
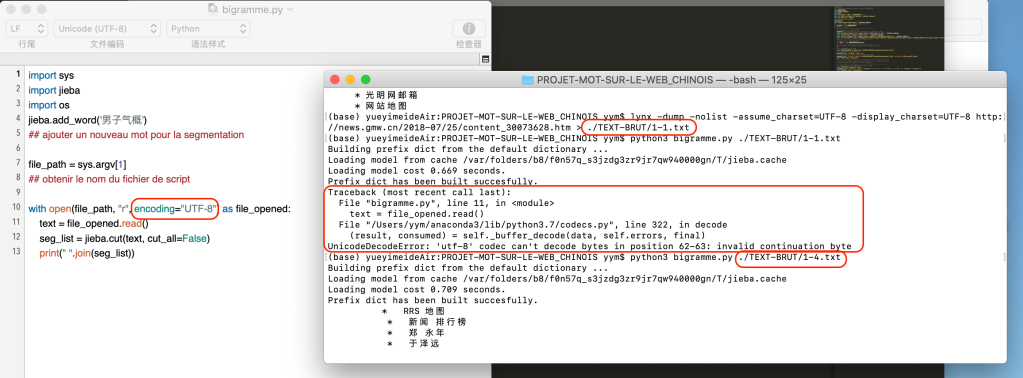
À cause de ce problème, je n’ai pas pu créer les fichiers de l’index et du bigramme.
Pour régler ce problème, j’ai trouvé une solution en ligne. Mais cette page est en chinois, j’espère que cette page peut être utile pour les autres étudiants chinois.
Le lien : https://blog.csdn.net/qq_27056805/article/details/86469647?utm_source=app
Voici le script modifié qui marche bien pour segmenter le texte en chinois.
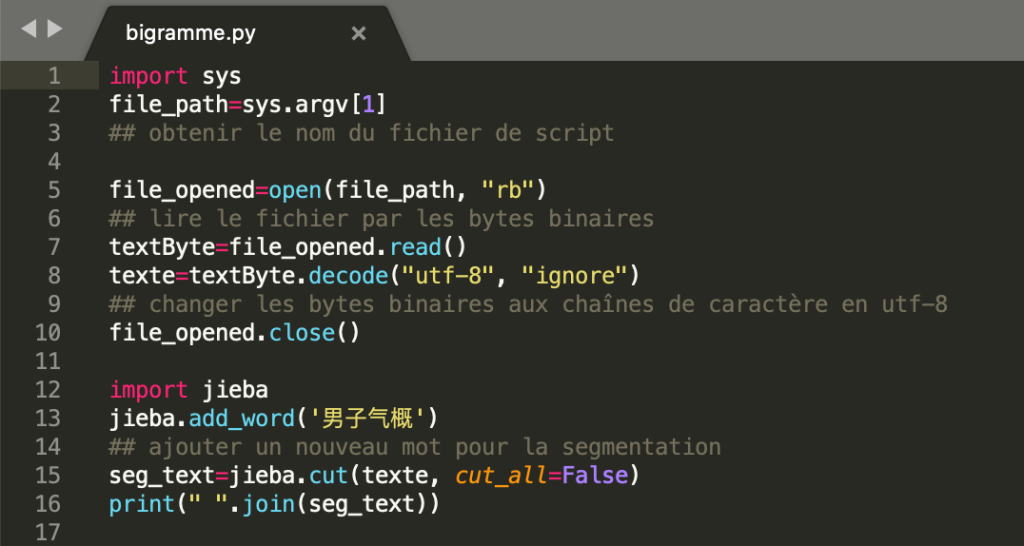
Puisque le chinois utilise plus souvent l’encodage « GBK » et « GB2312 », il faut d’abord ouvrir le texte en octet binaire, afin d’éviter le problème d’afficher causé par l’encodage. Et puis, on utilise ‘decode(« utf-8 », « ignore »)’ pour reconstruire le texte en utf-8 et on ignore les caractères qui ne sont pas connus par utf-8. Ensuite, on peut utiliser l’outil Jieba pour ajouter les nouveaux règles de segmentation et segmenter le texte.
Avec ce script, la segmentation du texte en chinois est bien faite.
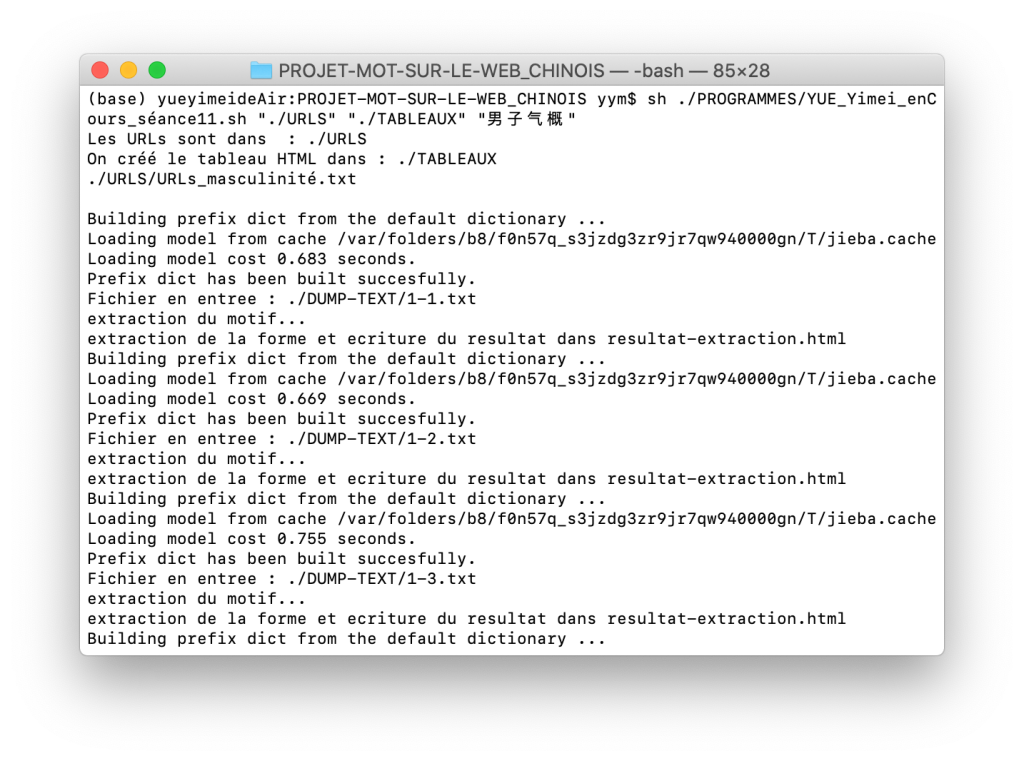

Billet très clair !!!
Bravo
SF
J’aimeAimé par 1 personne
Merci beaucoup.
J’aimeJ’aime